Printing recursive text tokens, two-letter tokens and control codes
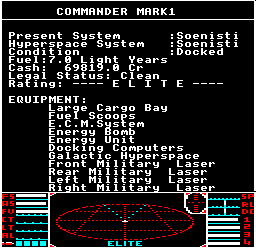
There are lots of routines that print text in Elite, covering everything from the formatting of huge decimal numbers to printing individual spaces. For example, the Status Mode screen uses a whole range of those routines to print our commander's status:
Under the hood, the game's text system boils down to the following core routines:
- TT27, which prints recursive text tokens from the QQ18 table and two-letter tokens from the QQ16 table
- DETOK and DETOK3, which print extended text tokens (in the enhanced disc, 6502 Second Processor and BBC Master versions only)
- BPRNT, which prints decimal numbers
- TT26, which pokes individual characters into screen memory
This deep dive looks at the first of these three routines, TT27, which forms the heart of Elite's text tokenisation system. There are three types of text token used by all versions of Elite - recursive tokens, two-letter tokens and control codes - so let's look at how they all work.
Tokenisation
------------
Elite uses a tokenisation system to store most of the text that it displays in the game. This enables the game to store strings more efficiently than would be the case if they were simply inserted into the source code using EQUS, and it also makes it possible to build text strings, like system names, using procedural generation.
To support tokenisation, characters are printed to the screen using a special subroutine, TT27, which not only supports the usual range of letters, numbers and punctuation, but also three different types of token. When printed, these tokens get expanded into longer strings, which enables the game to squeeze a lot of text into a small amount of storage.
To print something, you pass a character code in A to the printing routine at TT27. The character code determines what gets printed, as follows:
Code in A Text or token that gets printed --------- ------------------------------------------------------------- 0-13 Control codes 0-13 14-31 Recursive tokens 128-145 (i.e. print token number A + 114) 32-95 Normal ASCII characters 32-95 (0-9, A-Z and most punctuation) 96-127 Recursive tokens 96-127 (i.e. print token number A) 128-159 Two-letter tokens 128-159 160-255 Recursive tokens 0-95 (i.e. print token number A - 160)
Codes 32-95 represent the normal ASCII characters from " " to "_", so a value of 65 represents the letter A (as "A" has character code 65 in the BBC Micro's character set).
All other character codes (0-31 and 96-255) represent tokens, and they can print anything from single characters to entire sentences. In the case of recursive tokens, the tokens can themselves contain other tokens, and in this way long strings can be stored in very few bytes, at the expense of code readability and speed.
To make things easier to follow in the discussion and comments below, let's refer to the three token types like this, where n is the character code:
{n} Control code n = 0 to 13
<n> Two-letter token n = 128 to 159
[n] Recursive token n = 0 to 148
So when we say {13} we're talking about control code 13 ("crlf"), while <141> is the two-letter token 141 ("DI"), and [3] is the recursive token 3 ("DATA ON {current system}"). The brackets are just there to make things easier to understand when following the code, because the way these tokens are stored in memory and passed to subroutines is confusing, to say the least.
We'll take a look at each of the three token types in more detail below, but first a word about the two routines for printing characters in Elite.
The TT27 print subroutine
-------------------------
As mentioned above, Elite contains a subroutine at TT27 that prints out the character code given in the accumulator, and if that number refers to a token, then the token is expanded before being printed. This is how almost all of the text in the game gets put on the screen. For example, the following code:
LDA #65 JSR TT27
prints a capital A, while this code:
LDA #163 JSR TT27
prints recursive token number 3 (see below for more on why we pass a value of 163 instead of 3). This would produce the following if we were currently visiting the lore-heavy system of Tionisla:
DATA ON TIONISLA
This is because token 3 expands to the string "DATA ON {current system}". You can see this very call being used in routine TT25, which displays data on the selected system when red key f6 is pressed (this particular call prints the title at the top of the screen).
The ex print subroutine
-----------------------
There are 149 recursive tokens in all, numbered from 0 to 148, but the TT27 routine can only print tokens 0 to 145. So how do we print recursive tokens 146, 147 and 148?
Luckily there is another subroutine at ex that always prints the recursive token number given in the accumulator, so we can use that to print these tokens. So this, for example, is how we print "GAME OVER":
LDA #146 JSR ex
Incidentally, the ex subroutine is what TT27 calls when it has analysed the character code, determined that it is a recursive token, and subtracted 160 or added 114 as appropriate to get the token number, so calling ex directly with 146-148 in the accumulator is doing exactly the same thing, just without all the preamble.
Control codes: {n}
------------------
Control codes are in the range 0 to 13, and expand to the following when printed via TT27:
| Code | Shorthand in documentation | Expands to |
|---|---|---|
| 0 | {cash} CR{cr} | Current cash, right-aligned to width 9, then " CR", newline |
| 1 | {galaxy number} | Current galaxy number, right-aligned to width 3 |
| 2 | {current system name} | Current system name |
| 3 | {selected system name} | Selected system name (the crosshairs in the Short-range Chart) |
| 4 | {commander name} | Commander's name |
| 5 | FUEL: {fuel level} LIGHT YEARS{cr} CASH:{cash} CR{cr} | "FUEL: ", fuel level, " LIGHT YEARS", newline, "CASH:", {0}, newline |
| 6 | {sentence case} | Switch case to Sentence Case |
| 7 | {beep} | Beep |
| 8 | {all caps} | Switch case to ALL CAPS |
| 9 | {tab to column 21}: | Tab to column 21, then print a colon |
| 0 | {lf} | Line feed (i.e. move cursor down) |
| 1 | {cr} | Newline (i.e. carriage return and line feed) |
| 2 | {cr} | Newline (i.e. carriage return and line feed) |
| 3 | {cr} | Newline (i.e. carriage return and line feed) |
So a value of 4 in a tokenised string will be expanded to the current commander's name, while a value of 5 will print the current fuel level in the format "FUEL: 5.3 LIGHT YEARS", followed by a newline, followed by "CASH: ", and then control code 0 - which shows the amount of cash to one significant figure, right-aligned to a width of 9 characters - before finishing off with " CR" and another newline. The result is something like this, when displayed in Sentence Case:
Fuel: 6.7 Light Years Cash: 1234.5 Cr
If you press f8 to show the Status Mode screen, you can see control code 4 being used to show the commander's name in the title, while control code 5 is responsible for displaying the fuel and cash lines.
When talking about encoded strings in the code comments below, control characters are shown as {n}, so {4} expands to the commander's name and {5} to the current fuel.
By default, Elite prints words using Sentence Case, where the first letter of each word is capitalised. Control code {8} can be used to switch to ALL CAPS (so it acts like Caps Lock), and {6} can be used to switch back to Sentence Case. You can see this in action on the Status Mode screen, where the title and equipment headers are in ALL CAPS, while everything else is in Sentence Case. Tokens are stored using capital letters only, and each letter's case is determined by the logic in TT27 before it is printed.
Two-letter tokens: <n>
----------------------
Two-letter tokens expand to the following:
128 AL 129 LE 130 XE 131 GE 132 ZA 133 CE 134 BI 135 SO 136 US 137 ES 138 AR 139 MA 140 IN 141 DI 142 RE 143 A? 144 ER 145 AT 146 EN 147 BE 148 RA 149 LA 150 VE 151 TI 152 ED 153 OR 154 QU 155 AN 156 TE 157 IS 158 RI 159 ON
So a value of 150 in a tokenised string would expand to VE, for example. When talking about encoded strings in the code comments below, two-letter tokens are shown as <n>, so <150> expands to VE.
The set of two-letter tokens is stored in a two-byte lookup table at QQ16. This table is also used to generate system names procedurally, as described in the deep dive on generating system names.
Note that question marks in two-letter tokens are not printed, so token <143> expands to "A" rather than "A?". This allows names with an odd number of characters to be generated from sequences of two-letter tokens, though they do have to contain the letter A, as token <143> is the only one of its type.
Recursive tokens: [n]
---------------------
The binary file that is generated by this part of the main source file (WORDS9.bin) contains 149 recursive tokens, numbered from 0 to 148, which are stored at QQ18 (from &0400 to &06FF) in a tokenised form. These tokenised strings can include references to other tokens, hence "recursive".
When talking about encoded strings in the code comments below, recursive tokens are shown as [n], so [111] expands to "FUEL SCOOPS", for example, and [110] expands to "[102][104]S", which in turn expands to "EXTRA BEAM LASERS" (as [102] expands to "EXTRA " and [104] to "BEAM LASER").
The recursive tokens are numbered from 0 to 148, but because we've already reserved codes 0-13 for control characters, 32-95 for ASCII characters and 128-159 for two-letter tokens, we can't just send the token number straight to TT27 to print it out (sending 65 to TT27 prints "A", for example, and not recursive token 65). So instead, we use the following from the table above to work out what to send to TT27:
Code in A Text or token that gets printed --------- ------------------------------------------------------------- 14-31 Recursive tokens 128-145 (i.e. print token number A + 114) 96-127 Recursive tokens 96-127 (i.e. print token number A) 160-255 Recursive tokens 0-95 (i.e. print token number A - 160)
The first column is the number we need to send to TT27 in the accumulator to print the token described in the second column.
So, if we want to print recursive token 132, then according to the first row in this table, we need to subtract 114 to get 18, and send that to TT27.
Meanwhile, if we want to print token 101, then according to the second row, we can just pass that straight through to TT27.
Finally, if we want to print token 3, then according to the third row, we need to add 160 to get 163.
Note that, as described in the section on the ex routine above, you can't use TT27 to print recursive tokens 146-148, but instead you need to call the ex subroutine. The method described here only applies to recursive tokens 0-145.
How recursive tokens are stored in memory
-----------------------------------------
The 149 recursive tokens are stored one after the other in memory, starting at &0400, with each token being terminated by a null character (EQUB 0).
To complicate matters, the strings themselves are all EOR'd with 35 before being stored, and this process is repeated when they are read from memory (as EOR is reversible). This is done in the routine at TT50.
Note that if a recursive token contains another recursive token, then that token's number is stored as the number that would be sent to TT27, rather than the number of the token itself.
All of this makes it pretty challenging to work out how one would store a specific token in memory, which is why the source code uses a handful of macros to make life easier. They are:
CHAR n Insert ASCII character n n = 32 to 95 CONT n Insert control code n n = 0 to 13 TWOK 'x', 'x' Insert two-letter token "xy" "xy" is in the table above RTOK n Insert recursive token n n = 0 to 148
A side effect of all this obfuscation is that tokenised strings can't contain ASCII 35 characters ("#"). This is because ASCII "#" EOR 35 is 0, and the null character is already used to terminate our tokens in memory, so if you did have a string containing the hash character, it wouldn't print the hash, but would instead terminate at the character before.
Interestingly, there's no lookup table for each recursive token's starting point in memory, as that would take up too much space, so to get hold of the encoded string for a specific recursive token, the print routine runs through the entire list of tokens, character by character, counting all the nulls until it reaches the right spot. This might not be fast, but it is much more space-efficient than a lookup table would be. You can see this loop in the subroutine at ex, which is where recursive tokens are printed.
An example
----------
Given all this, let's consider recursive token 3 again, which is printed using the following code (remember, we have to add 160 to 3 to get the value to pass through to TT27):
LDA #163 JSR TT27
Token 3 is stored in the tokenised form:
D<145>A[131]{3}
which we could store in memory using the following (adding in the null terminator at the end and knowing that two-letter token 145 is "AT"):
CHAR 'D' TWOK 'A', 'T' CHAR 'A' RTOK 131 CONT 3 EQUB 0
As mentioned above, the values that are actually stored are EOR'd with 35, and token [131] has to have 114 taken off it before it's ready for TT27, so the bytes that are actually stored in memory for this token are:
EQUB 'D' EOR 35 EQUB 145 EOR 35 EQUB 'A' EOR 35 EQUB (131 - 114) EOR 35 EQUB 3 EOR 35 EQUB 0
or, as they would appear in the raw WORDS9.bin file, this:
EQUB &67, &B2, &62, &32, &20, &00
These all produce the same output, but the first version is rather easier to understand.
Now that the token is stored in memory, we can call TT27 with the accumulator set to 163, and the token will be printed as follows:
D The letter D "D"
<145> Two-letter token 145 "AT"
A The letter A "A"
[131] Recursive token 131 " ON "
{3} Control character 3 The selected system name
So if the system under the crosshairs in the Short-range Chart is Tionisla, this expands into "DATA ON TIONISLA", all of which is stored in just six bytes.